Chihuahua or Muffin?
Transfer learning is the bread and butter of image classification through Deep Learning. Training a deep neural network from scratch requires from tens of thousands to millions of images to reach what Jeremy Howard calls world-class accuracy (e.g. >= 95%). Luckily there’s a shortcut to almost jump-start the dataset creation problem and to quickly produce a tailored application for our specific classification needs. This shortcut is transfer learning. Transfer learning is a particular ML (Machine Learning) technique that allows to leverage a pre-trained neural network to do a job it was not meant for. In this case, I used the pre-trained version of ResNet-50, pre-trained with ImageNet images, to distinguish between chihuahua and muffins (and much more).

Following the excellent Fast.ai - Lesson 2 I’ve been able to use the Fast.ai library to replace the last fully connected layer of the ResNet-50 model with a new (untrained) FC layer with as many neurons as the number of classes of the problem. Then the whole model has been further trained (fine-tuned) through the unfreeze() function and a variable learning rate: the first convolutional layers were trained with a very low learning rate, while the last layers were trained with a higher LR. This makes the neural network use the kernels (= feature detectors) learned on the ImageNet dataset to excite the last layer of neurons, that now fire according to the new classification of images provided by the far smaller training set used to tackle the «Chihuahua or Muffin» sub-problem.
In this way the original problem is scaled down a lot and reaches a more manageable size. Much of the problem is now to download hundreds of images from Google Images (pip install google_images_download) check that those are really images, are readable images, are meaningful images and finally move them to create the dataset in it’s final form. Luckily, Fast.ai comes in our aid also in this aspect: the excellent ImageDataBunch class helps us to build our dataset simply starting from a folder structure with classes assigned to images according to their file names.
And this is the output of this Jupyter Notebook cell.

As you can see, Fast.ai also helps us visualize our dataset. It also provides functions to automatically clean our dataset: the verify_images function simply tries to read all the images in a folder and (optionally) deletes the images that are not readable.
Now that we have a clean dataset with hundreds of chihuahuas and muffins, we can start re-training our model. We first re-train without even unfreezing it. The magic here is performed by the fit_one_cycle() Fast.ai function.
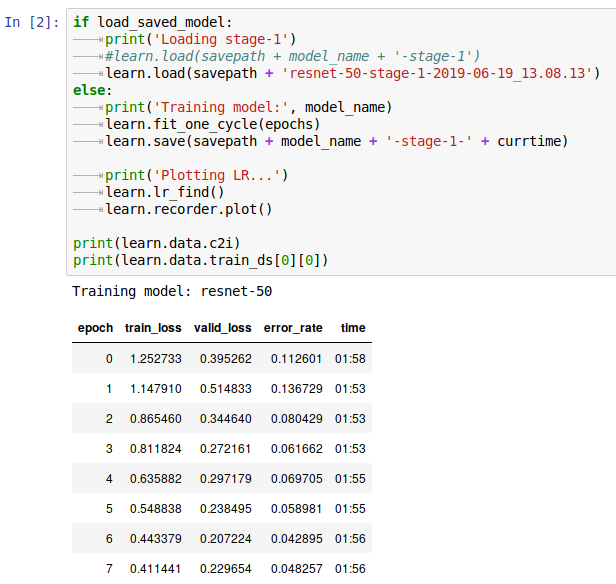
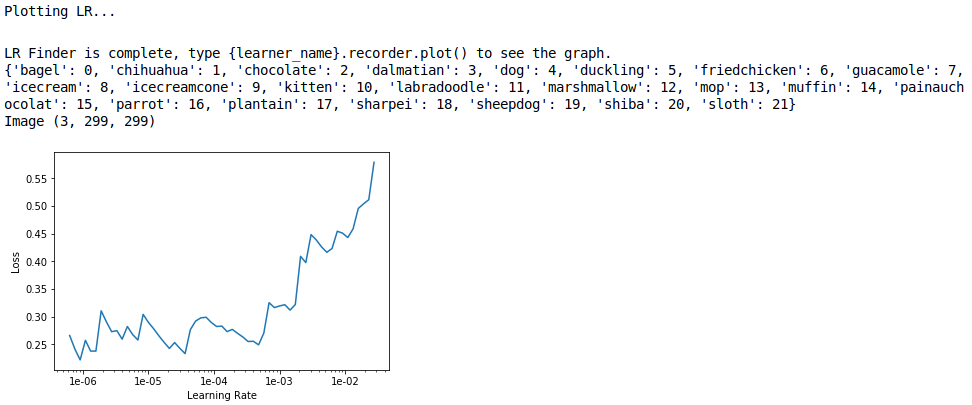
Vualà, 95% (world-class) accuracy. But we can even do slightly better1 via fine-tuning the model after unfreezing also the upper convolutional layers. Here Fast.ai comes again in our aid. Through the handy lr_find() function, it’s possible to find a range of learning rate values where the loss doesn’t explode (i.e. the training problem still converges towards a minimum and so it makes the network generalize better). The purpose of finding a valid LR range and actually using it as parameter to fit_one_cycle() is exquisitely and rigorously explained in this blog post that you should definitely read now before moving forward on this page.
Before unfreezing the network, we can also take a look at the so called top losses (with plot_top_losses()), the images that were wrongly classified and with the most confidence over the wrong classification decision.
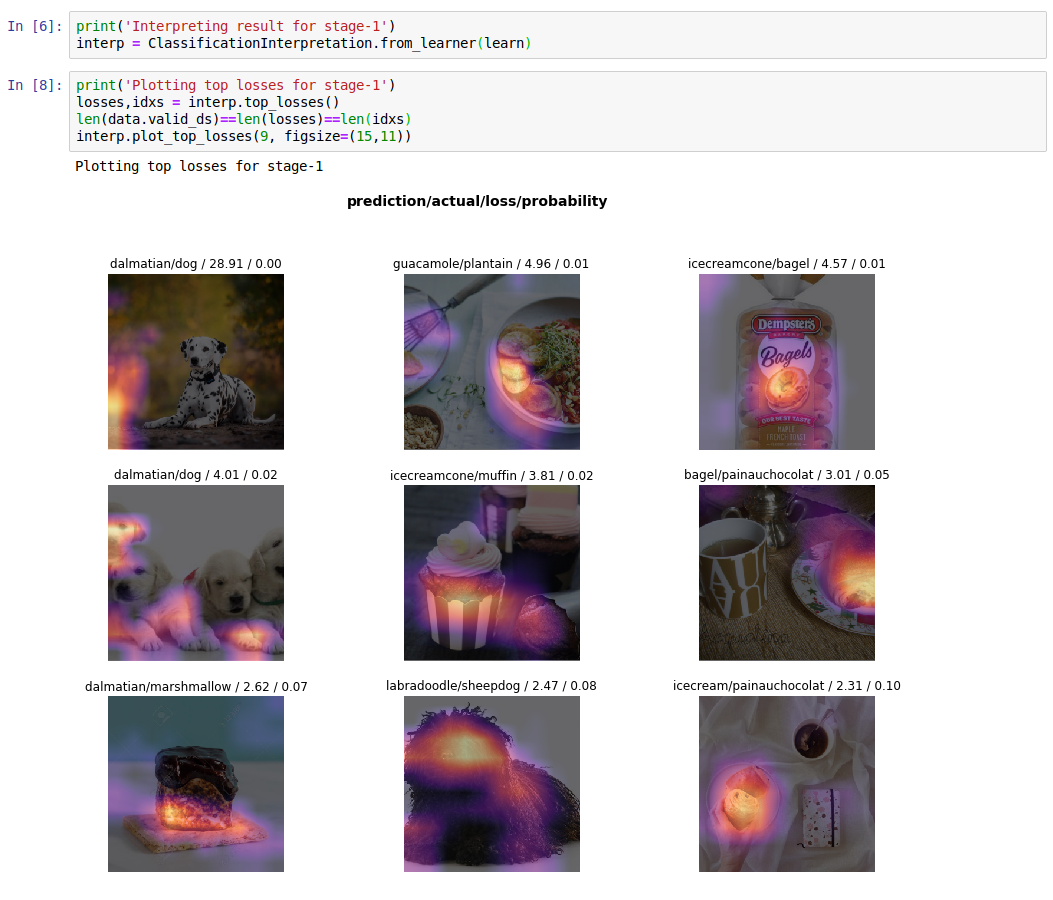
If we look a little bit carefully at the prediction/actual labels, we’ll find out that we originally misclassified one dalmatian putting it’s image in the dog/ directory. Then we also see a muffing that looks way too much similar to one of ours icecreamcones, a plaintain picture with too much guacamole-like greens aside, and so on. This kind of representation is extremely useful to shape the problem, both from a pure ML perspective (e.g. eliminating borderline pictures to make the algorithm confuse less) or the other way around, from a “philosophical” perspective (e.g. are we considering all the types of icecreamcones in the world, or someone calls this popsicle picture “icecreamcone” even if for us is clearly a popsicle?). These pictures are also overlaid to a heatmap that should highlight what portions of the image excited the neural network more. Sometimes this gives an hint, sometimes it doesn’t.
| A dalmatian in the dogs folder | A muffin that looks too much as an icecreamcone |
|---|---|
 |
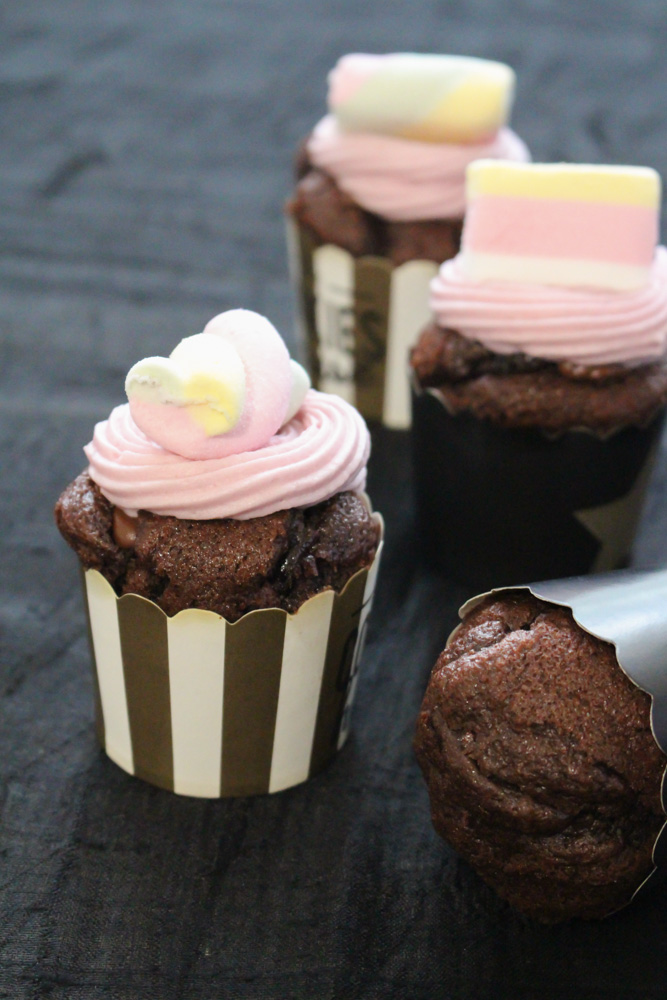 |
Finally, we can also take a look at the confusion matrix and at the most confused images in our setup. It takes just a quick look to see that we are misclassifying mostly different types of dogs.
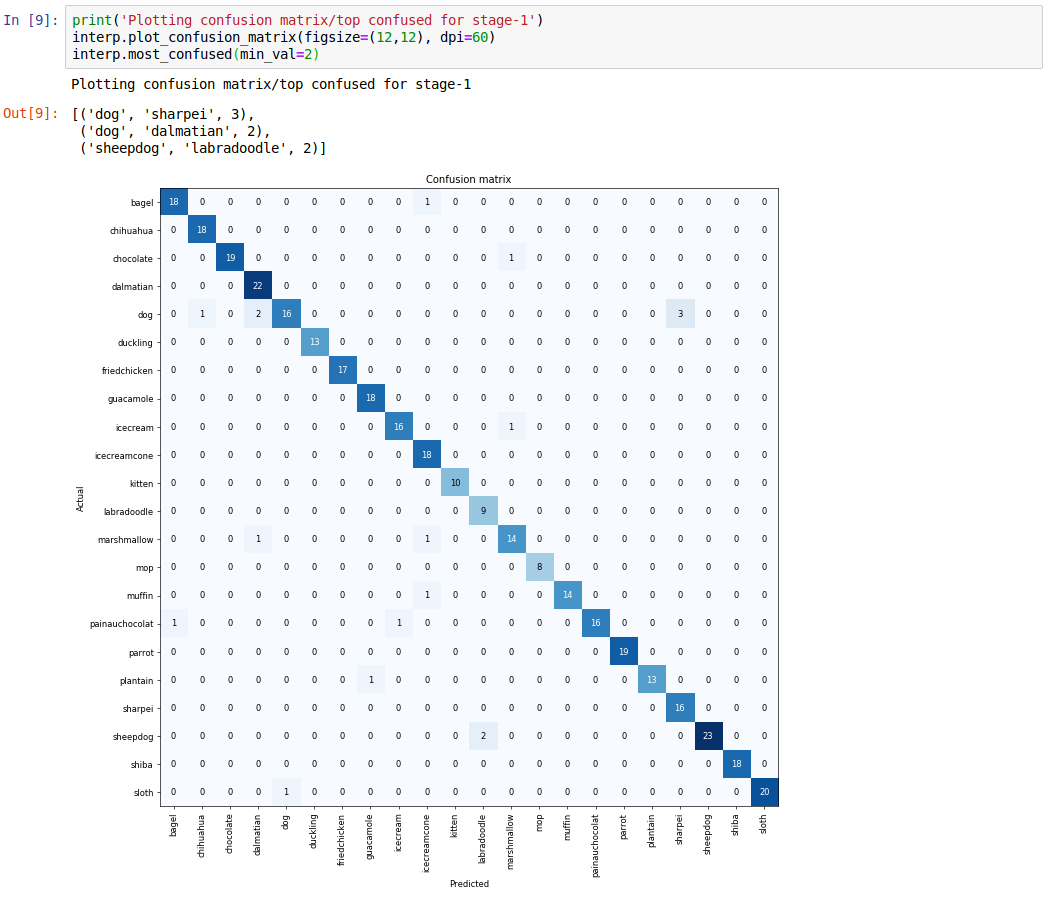
So that’s it, now we have a nice world class model for chihuahua and muffin classification, ready to be employed inside a docker container that serves a webpage. The awesomeness of all this, is that we managed to reach this amazing result without too much effort, mainly thanks to ResNet, transfer learning and the Fast.ai library.
-
uhm, after many cycles of retraining with different numbers of epochs, I didn’t manage to improve the error rate after unfreezing. ↩